
这周题做的不多 主要是去看基础还有就是去读码了 累啊 读码读起有点累 不晓得是不是蠢了还要去打个草稿推一下逻辑 但是这周我个人觉得是收益比较大的一周 比起无脑刷题我觉得这样更好
ctfplus - CTF+Binary练习题-Re-Day2
直接上个结论 这个题其实很简单 甚至wp都只有两句话,就是一个简单的异或加密。 但是我读代码结合der包一句一句读了一下午,我个人认为这个可以夯实底子也很锻炼线下真本事,慢慢动脑壳的自己读码对于后面肯定是有益的。可能事后很觉得浪费时间很没效率 但是也没办法,脑壳比较愚钝,只能慢慢来。给自己画个饼现在花的时间总是有回报的。刚好读码练习了也可以稍微兼顾一下解码。后面如果有机会去国赛是很有好处的。起码能看懂题不会坐冷板凳。做那么多题反正都是去读码 分析 找加密函数解码,刚刚上路感觉每步踩稳比较好,比起啥子都喂AI知识学到位才是关键。这道题分析暴露的问题很关键了 简单来说就是对指针有明显的学习短板 急需速补,还有就是解码了 慢慢学吧
拖入ida pro 直接找到主函数main F5 生成伪代码
可以通过读码来理清这个主函数的运行逻辑 (这里其实这个题给的很明显的,通常直接喂给ai就可以很简单的判断这道题的一个解题思路 但是作为初学者我对于这道题其实比较刻意的有练习自己的读码能力 也查到了自己在分析代码的一些漏洞 这是好事 也是当上大手子必备的事情 当然在分析代码的过程肯定会借助ai来理解学习)OK我们下面进行推理
__int64 __fastcall main(int a1, char **a2, char **a3)
{
__int64 v3; // rdx
__int64 v4; // rdx
__int64 v5; // rdx
_BYTE dest[36]; // [rsp+0h] [rbp-A0h] BYREF
_DWORD v8[4]; // [rsp+24h] [rbp-7Ch] BYREF
_DWORD v9[3]; // [rsp+34h] [rbp-6Ch]
_BYTE s[48]; // [rsp+40h] [rbp-60h] BYREF
const char *Congratulations__The_flag_is_correct.; // [rsp+70h] [rbp-30h]
const char *Incorrect_flag__please_try_again.; // [rsp+78h] [rbp-28h]
const char *flag_length_error; // [rsp+80h] [rbp-20h]
const char *Unmask_the_hidden_secret._Input_your_flag:_; // [rsp+88h] [rbp-18h]
char **v15; // [rsp+90h] [rbp-10h]
int v16; // [rsp+98h] [rbp-8h]
unsigned int v17; // [rsp+9Ch] [rbp-4h]
v17 = 0;
v16 = a1;
v15 = a2;
dword_404088 = a1;
qword_404090 = (__int64)a2;
Unmask_the_hidden_secret._Input_your_flag:_ = "Unmask the hidden secret. Input your flag: ";
sub_401220("Unmask the hidden secret. Input your flag: ", a2, a3);
flag_length_error = "flag length error";
Incorrect_flag__please_try_again. = "Incorrect flag, please try again.";
Congratulations__The_flag_is_correct. = "Congratulations! The flag is correct.";
memset(s, 0, 0x29u);
//到这里就是做一些初始化的工作 memset中
第一个参数 s:要初始化的目标内存地址,这里是存储用户输入 flag 的字符数组。
第二个参数 0:要填充的数值(以字节为单位),这里用 0 清空,避免内存中残留垃圾数据。
第三个参数 0x29u:填充的字节数,0x29 是十六进制,换算成十进制是 41 字节。
__isoc99_scanf("%s", s); //然后 __isoc99_scanf 读取用户输入的 flag 到 s 中。
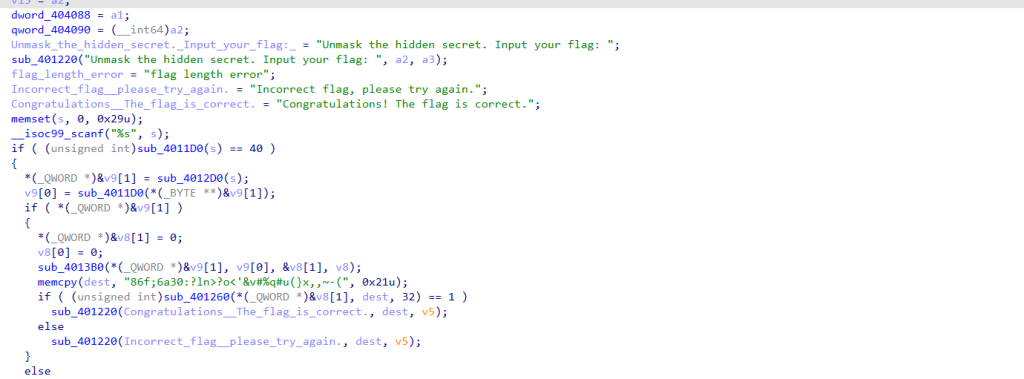
if ( (unsigned int)sub_4011D0(s) == 40 )//判断字符长度
{
*(_QWORD *)&v9[1] = sub_4012D0(s);
//调用 sub_4012D0(s) 处理输入字符串 s, 将函数sub_4012D0(s)返回的 64 位地址(指针),存入v9[1]起始的 8 字节内存,本质是指针存储与类型强制转换的组合操作
sub_4012D0(s):接收用户输入的 flag 字符串 s,返回一个 __int64 类型值(本质是 内存地址 / 指针,指向处理后的数据);
&v9[1]:取数组 v9 第 2 个元素的地址,原类型是 4 字节 DWORD*;
(_QWORD *)&v9[1]:强制将 4 字节指针转为 8 字节 QWORD*(适配 64 位系统地址长度),避免地址被截断;
*(_QWORD *)&v9[1]:解引用转换后的指针,将 sub_4012D0(s) 返回的地址写入 v9[1] 和 v9[2] 共 8 字节内存(覆盖两个 DWORD 元素)。
v9[0] = sub_4011D0(*(_BYTE **)&v9[1]);
//这行代码是 “获取sub_4012D0处理后的字符串 → 计算其长度 → 存储长度”,为后续核心处理函数sub_4013B0提供长度信息。
if ( *(_QWORD *)&v9[1] )//该判断的核心是 检查 sub_4012D0(s) 返回的指针是否有效(非空)
{
*(_QWORD *)&v8[1] = 0;// 初始化输出缓冲区 + 调用核心处理函数sub_4013B0,
v8[0] = 0;//综上:这两步是把v8数组的前 3 个元素(共 12 字节)初始化清零,v8作为sub_4013B0的输出缓冲区,清空是为了避免残留垃圾数据干扰结果。
sub_4013B0(*(_QWORD *)&v9[1], v9[0], &v8[1], v8);
//第 1 个参数:*(_QWORD *)&v9[1] → 输入数据(sub_4012D0处理后的字符串指针);
第 2 个参数:v9[0] → 输入数据的长度(strlen计算结果);
第 3 个参数:&v8[1] → 输出缓冲区的核心地址(存储处理后的关键数据);
第 4 个参数:v8 → 输出缓冲区的辅助信息(可能是长度计数或状态标记,已初始化为 0)。
memcpy(dest, "86f;6a30:?ln>?o<'&v#%q#u(}x,,~-(", 0x21u);
// 将固定字符串复制到目标缓冲区dest
if ( (unsigned int)sub_401260(*(_QWORD *)&v8[1], dest, 32) == 1 )
//sub_401260(...):这个函数比较 sub_4013B0 生成的结果和 dest 中的样本数据。如果比较结果相等(返回值为 1),则输出成功信息;否则输出失败信息。
sub_401220(Congratulations__The_flag_is_correct., dest, v5);
else
sub_401220(Incorrect_flag__please_try_again., dest, v5);
}
else
{
sub_401220(Incorrect_flag__please_try_again., s, v4);
return 0;
}
}
else
{
sub_401220(flag_length_error, s, v3);
return 0;
}
return v17;
}ok 上面就是main函数的内容以及读码 我们可以发现这个程序的一些东西
原始 flag →(sub_4012D0 变换)→ 中间数据 A →(sub_4013B0 算法)→ 中间数据 B →(sub_401260 比较)→ dest(已知)
我们先来看12D0
char *__fastcall sub_4012D0(const char *s)
{
__int64 v1; // rdx
char *dest; // [rsp+0h] [rbp-20h]
int v4; // [rsp+14h] [rbp-Ch]
v4 = strlen(s);
//计算s的技术长度 存入v4
if ( strncmp(s, "geesec{", 7u) || s[v4 - 1] != 125 )
//检查s前7个字符是不是geesec{ (如果不是 返回非0值 条件成立)
//s[v4 - 1] != 125 检测最后一个字符是否为}(ASCII码125)
{
sub_401220("flag format is incorrect", "geesec{", v1);
exit(-2); //C 语言中终止程序运行的系统调用相关函数
}
dest = (char *)malloc(0x21u);
// malloc是 C 语言动态内存分配函数,从堆区申请指定字节数的内存,返回指向该内存起始地址的指针 0x21u是十六进制常量(十进制 33)
//(char *)将malloc返回的void*通用指针强制转为char*,适配dest的字符指针类型,确保后续可按字节操作内存(如存储字符串)。33 字节足够容纳最长 32 个有效字符 + 1 个字符串结束符\0。
if ( !dest )
exit(0);
memset(dest, 0, 0x21u);
//是内存分配失败的错误处理逻辑,核心作用是避免程序因内存分配失败导致崩溃。
将 dest 指向的 33 字节(0x21 十六进制 = 33 十进制)内存空间全部初始化为 0
strncpy(dest, s + 7, v4 - 8);
//从字符串 s 中提取指定区间的子串,复制到目标缓冲区 dest,是逆向中常见的 “格式剥离” 操作。
return dest;
}可以看到12D0计算对于flag格式的一个明确和识别
再看一下13B0
int i; // [rsp+4h] [rbp-2Ch]
_BYTE *v6; // [rsp+8h] [rbp-28h]
v6 = malloc(size);
//根据输入数据的长度 size,动态分配一块相同大小的内存空间,用于存储变换后的结果。
if ( !v6 )
{
fprintf(stderr, "Memory allocation failed\n");
exit(-1);
}
for ( i = 0; i < size; ++i )
v6[i] = i ^ *(_BYTE *)(s + i);
//这是一段 逐字节异或(XOR)变换代码,核心逻辑是对输入数据s按索引i做异或运算,结果存 入数组v6
遍历范围:从索引0到size-1(共size个字节),size是输入数据s的有效长度。
作用:逐个处理s的每个字节。
i:当前字节的索引(0、1、2...size-1),作为异或的 “密钥”(逐字节变化的密钥)。
*(s + i):等价于s[i],取输入数据s第i个字节的内容(强制转为_BYTE确保按 1 字节读取)。
^:异或运算符,特点是 “两次异或同一值可还原原始数据”(可逆)。
结果:将索引i与s[i]异或后的结果,存入输出数组v6的第i位。
异或运算规则:相同位为 0,不同位为 1(如 0 ^ 0 = 0,1 ^ 1 = 0,0 ^ 1 = 1)。
*a3 = v6;
*a4 = size;
return a4;
}我们可以发现这就是一个简单的异或 要破解 flag,需要从目标比对字符串("86f;6a30:?ln>?o<'&v#%q#u(}x,,~-(")出发,对每个字节执行相同的异或操作(i ^ 目标字节),即可还原出原始的核心内容。
#include<stdio.h>
int main(void){
char t[32];
gets(t);
for(int i=1;i<=32;i++){
printf("%c",(int)t[i-1]^(i-1));
}
}
输入86f;6a30:?ln>?o<'&v#%q#u(}x,,~-(,得到flag,然后补上脑袋屁股
geesec{87d82d5726fe22a377d01d5b0db70c37}这个是c语言的,鱼丸说敲jo本最好用py,高中用py玩过noip 但是我已经忘完了 四级以后花一周捡一下。
指针
指针(Pointer) 是编程语言中的一个核心概念,它本质上是一个变量,其存储的值不是普通的数据(如整数、字符),而是另一个变量 / 数据在内存中的地址。可以把内存想象成一个巨大的储物柜,每个储物柜有唯一的编号(内存地址)。指针就像是一张写着储物柜编号的纸条,通过这个编号,你就能找到对应的储物柜并存取里面的东西。
作用:
间接访问:通过指针可以间接地读取或修改它指向的内存地址中的数据。
动态内存管理:在运行时灵活地分配和释放内存(如 malloc/free)。
函数参数传递:实现函数对实参的修改(传址调用)。
处理复杂数据结构:是数组、链表、树等结构的基础。
int num = 100; // 在内存地址 0x7ffeefbff5c4 处存储值 100
int *p = # // 指针变量 p 存储的是 num 的地址:0x7ffeefbff5c4num 是普通变量,占用内存并存储实际值。
p 是指针变量,它也占用内存(64 位系统中占 8 字节),但存储的是另一个变量的地址。
通过 *p 可以访问地址 0x7ffeefbff5c4 中的值,即 100。
回到刚刚那个题
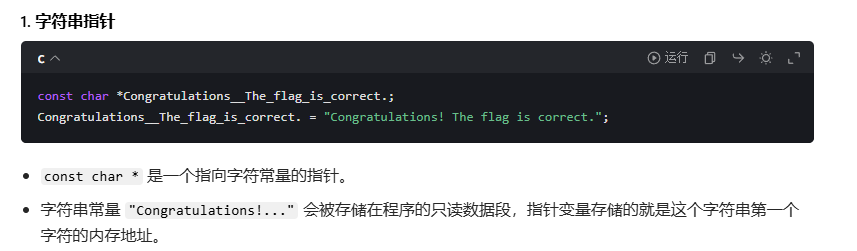
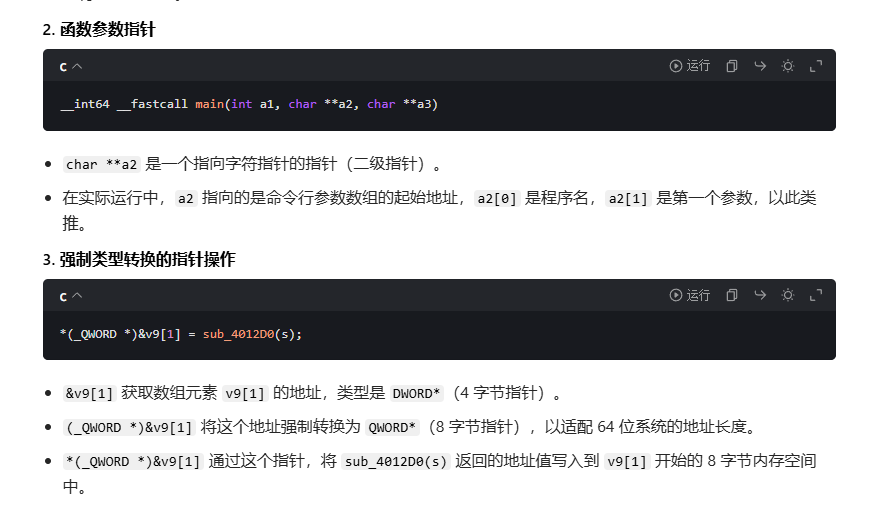
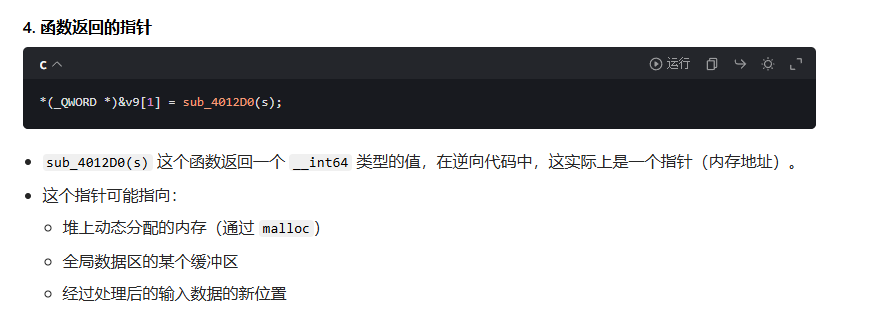
- 指针是地址:指针变量存储的是内存地址,而非数据本身。
- 间接访问:通过解引用操作符
*,可以访问指针指向地址中的数据。 - 类型匹配:指针的类型决定了它能指向的数据类型和内存操作的粒度(如
char*操作 1 字节,int*操作 4 字节)。
在逆向分析中,识别指针的类型转换和指向的数据,是理解程序内存布局和数据流向的关键。
CTF++-REVERSE-幸运数字
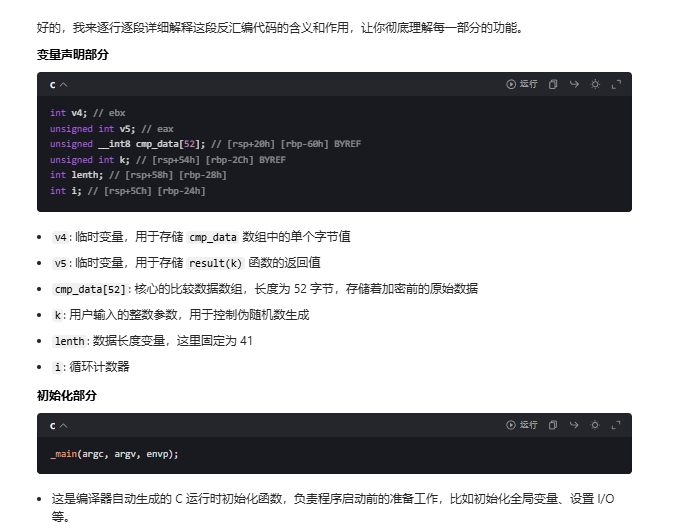
int __fastcall main(int argc, const char **argv, const char **envp)
{
int v4; // ebx
unsigned int v5; // eax
unsigned __int8 cmp_data[52]; // [rsp+20h] [rbp-60h] BYREF
unsigned int k; // [rsp+54h] [rbp-2Ch] BYREF
int lenth; // [rsp+58h] [rbp-28h]
int i; // [rsp+5Ch] [rbp-24h]
_main(argc, argv, envp);、
//这是反汇编中常见的编译器生成代码(非标准 C 语法),通常是对程序真正入口函数的调用(类似 main 函数的内部初始化调用),作用是传递命令行参数(argc 参数个数、argv 参数数组、envp 环境变量数组),完成程序启动的基础初始化,与后续数据加密逻辑无关。
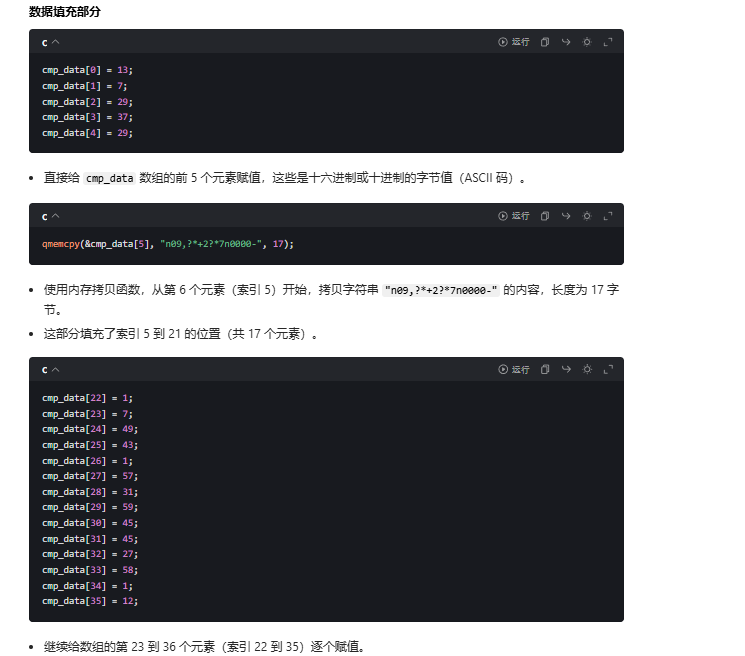
cmp_data[0] = 13;
cmp_data[1] = 7;
cmp_data[2] = 29;
cmp_data[3] = 37;
cmp_data[4] = 29;
qmemcpy(&cmp_data[5], "n09,?*+2?*7n0000-", 17);
//qmemcpy 是快速内存拷贝函数(类似标准库 memcpy,常见于编译器内置或系统底层实现,拷贝效率更高);从 cmp_data[5] 开始,拷贝字符串 "n09,?*+2?*7n0000-" 的 17 个字节(覆盖索引 5-21);
从 cmp_data[36] 开始,拷贝字符串 "o96*#" 的 5 个字节(覆盖索引 36-40)。
cmp_data[22] = 1;
cmp_data[23] = 7;
cmp_data[24] = 49;
cmp_data[25] = 43;
cmp_data[26] = 1;
cmp_data[27] = 57;
cmp_data[28] = 31;
cmp_data[29] = 59;
cmp_data[30] = 45;
cmp_data[31] = 45;
cmp_data[32] = 27;
cmp_data[33] = 58;
cmp_data[34] = 1;
cmp_data[35] = 12;
//直接赋值:对前 4 个元素、中间第 22-35 个元素,直接指定单个字节值(如 13 7 49 等,本质是 ASCII 码或自定义加密字节);
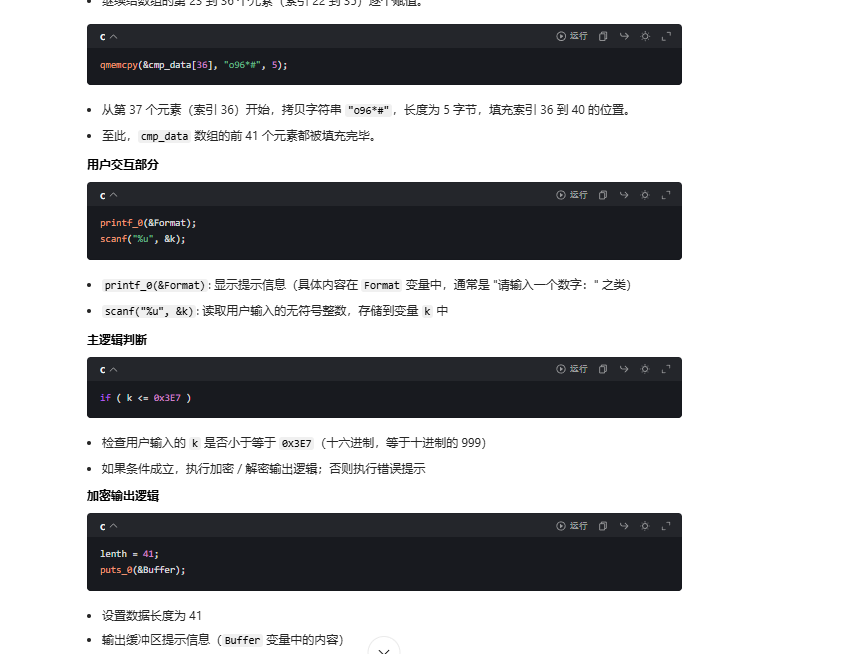
qmemcpy(&cmp_data[36], "o96*#", 5);
//&cmp_data[36] 表示数组 cmp_data 第 36 个元素(下标从 0 开始)的内存地址,即从该位置开始写入数据;字符串常量 "o96*#",其本质是连续的 ASCII 字节序列(对应字 节:'o'(0x6F)、'9'(0x39)、'6'(0x36)、'*'(0x2A)、'#'(0x23)
printf_0(&Format);
scanf("%u", &k);//读取用户输入的无符号整数(非负整数),并存储到变量 k 中,
if ( k <= 0x3E7 )
{
lenth = 41;
puts_0(&Buffer);
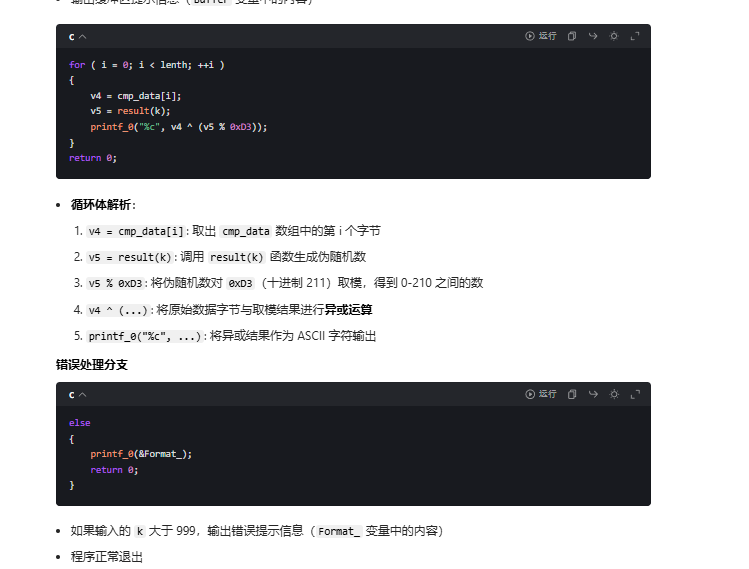
for ( i = 0; i < lenth; ++i )
{
v4 = cmp_data[i];
v5 = result(k);
printf_0("%c", v4 ^ (v5 % 0xD3));
}
return 0;
}
else
{
printf_0(&Format_);
return 0;
}
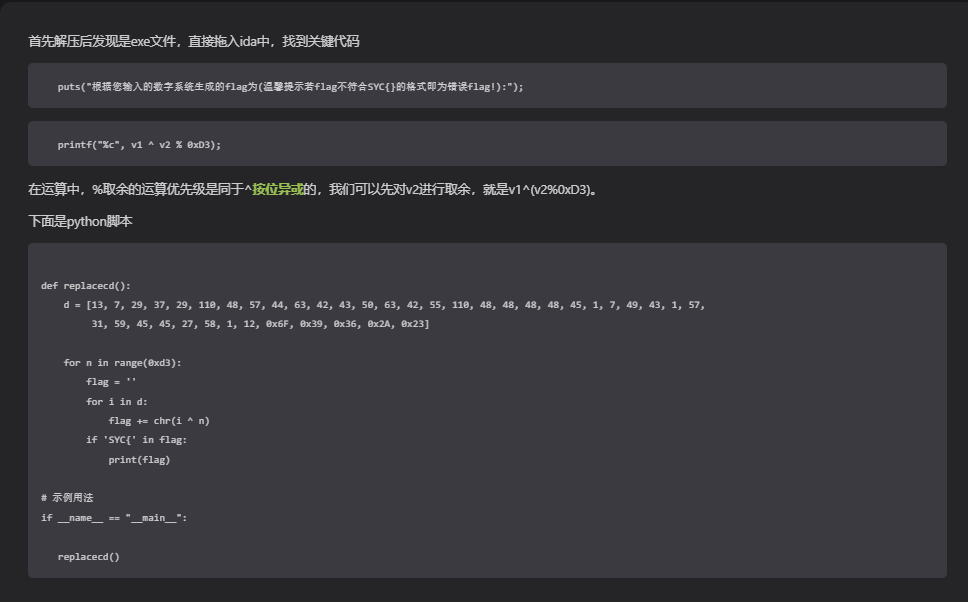
}可以直接看到result(k)就是关键 这里可以直接暴力破解得到某个值可以输出flag 依旧ai
#include <stdio.h>
#include <string.h>
unsigned int result(unsigned int k) {
unsigned int seed = 1;
for (unsigned int i = 0; i < k; i++) {
seed = (1103515245 * seed + 12345) & 0x7FFFFFFF;
}
return seed;
}
int main() {
unsigned char cmp_data[52];
int length = 41;
// 初始化 cmp_data 数组
cmp_data[0] = 13;
cmp_data[1] = 7;
cmp_data[2] = 29;
cmp_data[3] = 37;
cmp_data[4] = 29;
memcpy(&cmp_data[5], "n09,?*+2?*7n0000-", 17);
cmp_data[22] = 1;
cmp_data[23] = 7;
cmp_data[24] = 49;
cmp_data[25] = 43;
cmp_data[26] = 1;
cmp_data[27] = 57;
cmp_data[28] = 31;
cmp_data[29] = 59;
cmp_data[30] = 45;
cmp_data[31] = 45;
cmp_data[32] = 27;
cmp_data[33] = 58;
cmp_data[34] = 1;
cmp_data[35] = 12;
memcpy(&cmp_data[36], "o96*#", 5);
// 暴力破解寻找有意义的输出
for (unsigned int k = 1; k <= 999; k++) {
unsigned int v5 = result(k);
unsigned int key = v5 % 0xD3;
printf("k=%d: ", k);
for (int i = 0; i < length; ++i) {
printf("%c", cmp_data[i] ^ key);
}
printf("\n");
}
return 0;
}这一题其实一点点的模糊逻辑 我把ai的粘上来吧 后面方便我回顾

然后我贴一个师傅的wp方便参考
极客大挑战2023-Re-点击就送的逆向题
这个题其实做过 好像是week1的题了 但是跟着ai用的kali去解的题 这次我想自己分析 这个题读下来就是纯汇编 有一种之前看的汇编白看了的感觉 呆呆鸟学长可以稍微提点一二,还有就是数据结构那块感觉有点抽象飘渺了 可能是做题的时候老壳有点men,我没get到这个题的数据处理方式,总的来说这个题比较值得积累从读码层面 也刚好打开我对于汇编那块实践不到位的问题。很多逆向也不是反汇编可以去完成的 还有之前kali的做法我也要去看看原理 读码有点太慢了感觉 但是确实很有收获啊 基本上稍微已经可以抓到一些些自觉了 就比如看主函数就可以大概了解一个大概的逻辑处理,不是一味的喂ai。当然ai确实更高效方便 我看李林枭做题也在用ai
.s文件 ida打不开 托txt瞅一眼看到是个汇编
.file "chal.c"
.text
.section .rodata
.LC0:
.string "%s"
.LC1:
.string "wrong!"
.LC2:
.string "good!"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
subq $96, %rsp
movq %fs:40, %rax
movq %rax, -8(%rbp)
xorl %eax, %eax
movabsq $5569930572732194906, %rax
movabsq $6219552794204983118, %rdx
movq %rax, -48(%rbp)
movq %rdx, -40(%rbp)
movabsq $6722278119083037265, %rax
movabsq $5570191165376843081, %rdx
movq %rax, -32(%rbp)
movq %rdx, -24(%rbp)
movb $0, -16(%rbp)
leaq -80(%rbp), %rax
movq %rax, %rsi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call __isoc99_scanf@PLT
movl $0, -84(%rbp)
jmp .L2
.L3:
movl -84(%rbp), %eax
cltq
movzbl -80(%rbp,%rax), %eax
addl $7, %eax
movl %eax, %edx
movl -84(%rbp), %eax
cltq
movb %dl, -80(%rbp,%rax)
addl $1, -84(%rbp)
.L2:
cmpl $31, -84(%rbp)
jle .L3
leaq -48(%rbp), %rdx
leaq -80(%rbp), %rax
movq %rdx, %rsi
movq %rax, %rdi
call strcmp@PLT
testl %eax, %eax
jne .L4
leaq .LC1(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
.L4:
leaq .LC2(%rip), %rax
movq %rax, %rdi
call puts@PLT
movl $0, %eax
movq -8(%rbp), %rdx
subq %fs:40, %rdx
je .L6
call __stack_chk_fail@PLT
.L6:
leave
ret
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:其实看不太懂 嘻嘻 我记得当时是用kali做的 我自己大概看了一下 L1 L2什么什么的不知道是不是寄存器 我就当是吧 好像是输入一段字符然后+7什么什么的处理 我自己读不懂很难受了 交给ai吧
main:
endbr64 ; 安全机制指令,与功能无关
pushq %rbp ; 保存旧的基址指针
movq %rsp, %rbp ; 设置新的基址指针,建立栈帧
subq $96, %rsp ; 分配96字节的栈空间
movq %fs:40, %rax ; 从fs段寄存器获取栈保护cookie
movq %rax, -8(%rbp) ; 保存cookie到栈上
xorl %eax, %eax ; 将eax寄存器清零
movabsq $5569930572732194906, %rax ; 加载第一个64位立即数
movabsq $6219552794204983118, %rdx ; 加载第二个64位立即数
movq %rax, -48(%rbp) ; 存储到栈上偏移-48处
movq %rdx, -40(%rbp) ; 存储到栈上偏移-40处
movabsq $6722278119083037265, %rax ; 加载第三个64位立即数
movabsq $5570191165376843081, %rdx ; 加载第四个64位立即数
movq %rax, -32(%rbp) ; 存储到栈上偏移-32处
movq %rdx, -24(%rbp) ; 存储到栈上偏移-24处
movb $0, -16(%rbp) ; 存储NULL终止符
leaq -80(%rbp), %rax ; 计算输入缓冲区地址(栈上偏移-80处)
movq %rax, %rsi ; 将缓冲区地址放入rsi(scanf的第二个参数)
leaq .LC0(%rip), %rax ; 加载格式字符串"%s"的地址
movq %rax, %rdi ; 将格式字符串地址放入rdi(scanf的第一个参数)
movl $0, %eax ; 清零eax,表示没有浮点参数
call __isoc99_scanf@PLT ; 调用scanf函数读取用户输入
movl $0, -84(%rbp) ; 初始化计数器i=0,存储在栈上偏移-84处
jmp .L2 ; 跳转到循环条件判断
.L3: ; 循环体开始
movl -84(%rbp), %eax ; 将计数器i加载到eax
cltq ; 将eax中的32位整数转换为64位(符号扩展)
movzbl -80(%rbp,%rax), %eax ; 读取输入字符串的第i个字符(零扩展)
addl $7, %eax ; 将字符值加7
movl %eax, %edx ; 保存结果到edx
movl -84(%rbp), %eax ; 再次加载计数器i
cltq ; 转换为64位
movb %dl, -80(%rbp,%rax) ; 将加7后的字符写回原位置
addl $1, -84(%rbp) ; 计数器i++
.L2: ; 循环条件判断
cmpl $31, -84(%rbp) ; 比较i和31
jle .L3 ; 如果i <= 31,跳回循环体大概懂了 实际发现它的主要目的是把四个十进制数存到一个一起,发现一个数字正好8x8=64位,够8个字节,然后编码为32长字符 每个字的ascii码+7得到另一串文本,与上面的字符比较,判断正误
依旧ai囧本
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char in[32];
char t[33];
long long p1 = 5569930572732194906ULL;
long long p2 = 6219552794204983118ULL;
long long p3 = 6722278119083037265ULL;
long long p4 = 5570191165376843081ULL;
memcpy(&t[0], &p1, 8);
memcpy(&t[8], &p2, 8);
memcpy(&t[16], &p3, 8);
memcpy(&t[24], &p4, 8);
t[32] = 0;
for (int i = 0; i < 32; i++) {
in[i] = t[i] - 7;
printf("%c",in[i]);
}
getchar();
return 0;
}SYC{SYCTQWEFGHYIICIOJKLBNMCVBFGHSDFF}
BaseUpx
又来玩脱壳了 有个更尴尬的就是我有个不错的脱壳工具直接秒脱 就emmmm 没难度
看到base 64了吧 emmmmmm 基本上就这样 但是我要看看写的啥
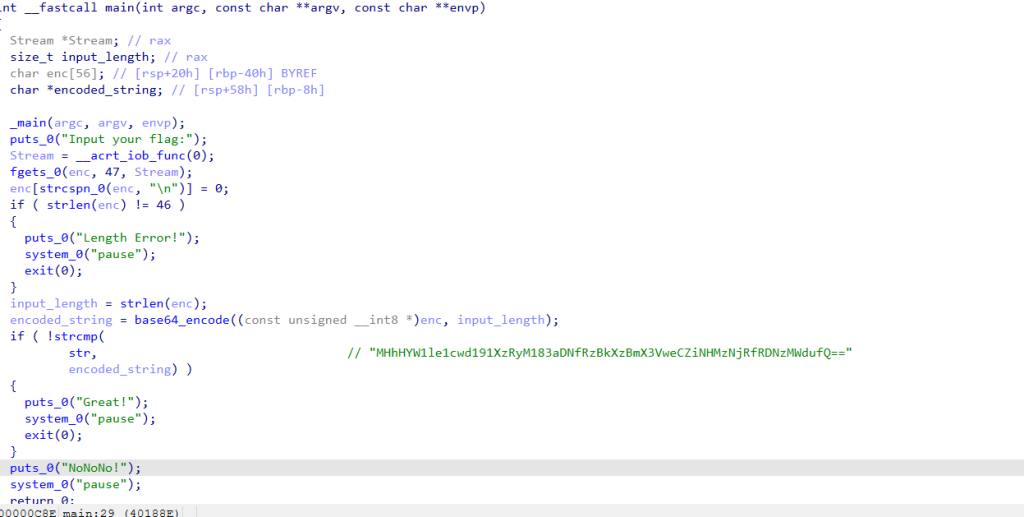
int __fastcall main(int argc, const char **argv, const char **envp)
{
Stream *Stream; // rax
size_t input_length; // rax
char enc[56]; // [rsp+20h] [rbp-40h] BYREF
char *encoded_string; // [rsp+58h] [rbp-8h]
//Stream *Stream: 定义一个文件流指针,用于标准输入
size_t input_length: 存储输入字符串的长度
char enc[56]: 定义一个 56 字节的字符数组,用于存储用户输入
char *encoded_string: 指针,用于存储 Base64 编码后的字符串
_main(argc, argv, envp);
puts_0("Input your flag:");
Stream = __acrt_iob_func(0);
//__acrt_iob_func(0): 获取标准输入流(stdin)的指针
fgets_0(enc, 47, Stream): 从标准输入读取最多 46 个字符(+1 个终止符)到enc数组中
fgets_0(enc, 47, Stream);
enc[strcspn_0(enc, "\n")] = 0;
if ( strlen(enc) != 46 )
{
puts_0("Length Error!");
system_0("pause");
exit(0);
}
input_length = strlen(enc);
encoded_string = base64_encode((const unsigned __int8 *)enc, input_length);
if ( !strcmp(
str, // "MHhHYW1le1cwd191XzRyM183aDNfRzBkXzBmX3VweCZiNHMzNjRfRDNzMWdufQ=="
encoded_string) )
{
puts_0("Great!");
system_0("pause");
exit(0);
}
puts_0("NoNoNo!");
system_0("pause");
return 0;
}
Comments NOTHING